
데이터 구조 (data structure)
앞에서 여러 데이터들을 살펴보고, 각 데이터를 저장하는 수단으로서 변수를 살펴보았다. 데이터와 변수 간의 관계를 되돌아 본다면, 1개의 데이터를 저장하기 위해서는 1개의 변수가 필요했었다. 즉, 하나의 이름(변수명)으로는 1개의 데이터 밖에 저장하지 못한다는 제한이 존재한다.
우리가 실제 데이터를 다루다 보면, 여러개의 데이터를 동시에 다루는 경우가 많다. 몇가지 예를 보자.
나는 A 라는 기업의 판매팀장이다. 작년 한해의 총매출을 집계하기 위해 월별 판매액을 총합하는 연산을 해야 한다.
위의 "나"는 몇 개의 데이터를 다루고 있나? 작년 1월부터 12월 까지의 월별 매출 데이터 12개와 그 데이터를 모두 더한 총매출 데이터 1개 해서 총 13개의 데이터를 다루고 있다. 1개의 변수는 1개의 데이터 밖에 저장할 수 없다면, 이 문제의 경우 변수가 몇개 필요하다? 그렇다. 13개가 필요하다.
또 다른 예를 살펴 보자.
나는 어느 초등학교 4학년 담임 선생님이다. 우리 반 학생들은 모두 30명이다. 이번에 국어, 영어, 수학 등 3개 과목 시험을 치렀는데, 그 결과로서 학생별 평균점수와 석차를 계산하고자 한다.
위의 "나"는 몇 개의 데이터를 다루고 있나? 학생 한 명당 국어점수, 영어 점수, 수학점수 데이터가 3개씩 있으므로, 반 학생 전체의 점수 데이터는 90개이다 (30*3=90). 각 학생별로 평균점수 데이터가 추가로 계산되므로 30개의 데이터가 추가되어 총 120개의 데이터가 만들어지게 된다. 1개의 데이터를 저장하기 위해서는 1개의 변수가 필요하니, 위의 "나"는 총 120개의 변수를 생성하고, 다루어야 한다.
이런 형태의 문제는 아주 흔하게 나타난다. 어떤 문제인가? 여러개의 데이터가 있다. 한데, 이 데이터들이 서로 연관되어 있다. 즉, 외부에서 보면 하나의 뭉치로 인식된다. (* 하나의 뭉치로 인식된다? 위의 첫번째 예제에서 다루어지는 데이터는 "월별 매출액 데이터", 두번째 예에서 다루어지는 데이터는 "시험성적 데이터"가 된다. *)
이렇게 하나의 뭉치로 다루어지는 데이터들을 하나의 변수로 다룰 수 있는 도구가 제공된다. 이러한 수단들을 일반의 프로그래밍 언어에서 데이터 구조 (data structure)라고 부르며, 파이썬에서는 리스트(list), 튜플(tupe), 딕셔너리(dictionary), 셋(set) 등의 데이터 구조가 기본적으로 제공되고 있다. (* 물론, 사용자가 새로운 데이터 구조를 정의할 수 있다. 객체기술을 설명하는 파트에서 자세히 살펴보자 *)
파이썬에서 기본적으로 제공되는 여러 형태의 데이터 구조가 있고, 또한 사용자가 다른 데이터 구조들을 확장하여 선언할 수 있지만, 모든 데이터 구조의 바탕에 있는 가장 중요한 데이터 구조는 리스트이다. 리스트를 이해하면 나머지 데이터 구조는 "거저 먹기" 이다.
리스트 (list)
리스트는 모든 형태의 데이터 구조 중에 가장 단순하면서 가장 중요하다. 나머지 모든 데이터 구조들은 리스트로 부터 파생되어 만들어진다고 생각하면 된다. (# 꼭 같지는 않지만, C/C++, Java 등 다른 언어에서는 배열(Array)이란 이름으로 불린다. 프로그래밍 문제에서 가장 활용도가 높은 것이 for 와 배열이 결합된 형태이다)
리스트는 2가지 특징을 가진다. (1) 그 내부적으로 여러개의 데이터를 저장할 수 있도록 여러개의 변수를 포함한다. (2) 전체 데이터가 하나의 뭉치다. 실제 생활에서 이와 비슷한 형태를 가진 것에는 기차(특히, 화물기차)가 있다. 기차는 여러개의 차량으로 구성되어 있다. 각 차량들은 '독립적으로' 물건을 싣거나 내릴 수 있다. 그리고, 모든 차량이 서로 연결되어 있을 때, 기관차가 첫번째 차량을 끌면 모든 차량이 '한꺼번에' 같이 움직이게 된다.
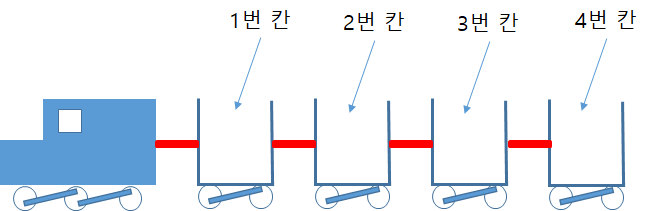
○ 리스트는 여러개의 데이터를 하나로 묶는다
뭔가가 여러개 있으면, 이것들을 구분하기 위해 구분자 (delimter) 역할을 하는 문자가 사용된다. 보통, 콤마( , )가 많이 사용된다. 파이썬에서도 콤마가 구분문자로 사용된다. 사람들의 일반 언어에도 콤마가 구분자로 사용되고 있다. 뻔한 얘기지만 예를 들어 본다면,
이번에 친구들이랑 캠핑을 가는데, 준비해야 할 물건들로, 텐트, 버너, 가스, 물, 삼겹살, 양념장 등이 있습니다.
그리고 리스트에서는 이것들을 하나로 묶어 주는 수단으로 대괄호 ([ ]) 를 사용한다. 리스트 데이터 구조의 간단한 예를 보면 아래와 같다.

리스트에 포함되어 있는 각 데이터를 요소 (element) 라고 부른다. 위의 리스트는 4개의 요소로 구성되어 있다.
데이터를 변수로 가리킬 수 있듯이, 리스트도 변수로 가리킬 수 있다. "위의 [1, 2, 3, 4] 라는 데이터를 a 라는 이름으로 부르겠다" 라고 한다면 아래와 같이 선언하면 된다. (# 변수에서 공부했던 내용과 전혀 다르지 않다.)

실제 a 라는 변수 이름은 전체 데이터를 가리키는 이름이 된다. 그래서, 아래와 같은 구문이 가능하다.

○ 리스트에 포함되어 있는 각 요소에 대해 접근할 수 있다.
보통 우리가 변수에 대해 접근(access)한다고 하면 (1) 변수에 다른 데이터를 저장하거나 (2) 그 변수에 저장되어 있는 데이터를 읽는 것을 말한다. (1)번 연산을 보통 store 또는 write 한다라고 하고 (2)번 연산을 retrieval 또는 read 한다라고 한다.
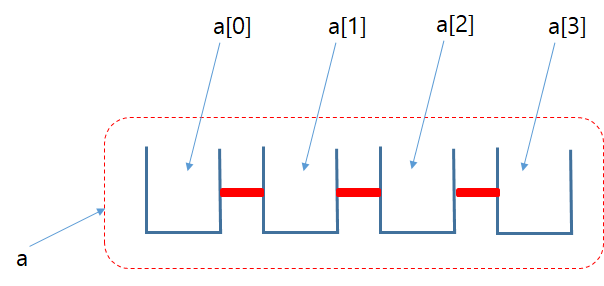
리스트는 내부적으로 여러개의 변수가 모여있는 구조이다. 즉, 리스트를 구성하는 각 요소(element)에 대한 접근이 가능하다. 다시 말해, 각 요소에 접근하여 값을 저장하거나 읽을 수 있다. 각 요소는 하나의 변수처럼 작동하게 되는데, 각 요소에 해당하는 변수의 이름은 리스트이름[첨자] 의 형태가 된다. 예를 들어, 아래와 같이 4개의 요소를 가지는 a 라는 이름의 리스트가 정의되면, 첫번째 요소에 해당하는 변수의 이름은 a[0], 두번째 요소는 a[1], 세번째 요소는 a[2], 네번째 요소는 a[3] 이 된다. 첨자의 시작은 0부터 시작한다는 것에 유의해야 한다.
실제, 리스트의 어떤 한 요소에 접근하여 값을 바꾸는 예제를 보면 다음과 같다. In[6]에서 a 리스트를 [1, 2, 3, 4]로 정의하였다. In[7]에[서 a[0]을 5로 바꾸었고, In[8]에서 실제 바뀐 것을 확인할 수 있었다.

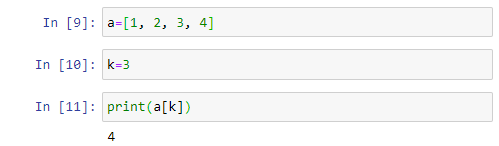
리스트 데이터 구조가, 다음에 살펴볼 for와 결합하여, 강력한 수단이 되는 것은 첨자에 수식(수 또는 식)이 들어갈 수 있다는 것이다. 아래의 코드에서 In[11]은 a[k] 값을 출력하는 명령어인데, 실제로 첨자에 변수 값이 사용되고 있다. In[10]에서 k 값은 3으로 정의되었으므로, In[11]의 print(a[k]) 명령어는 print(a[3])으로 실행하게 된다. 출력값이 a 리스트의 4번째 요소인 a[3] 값임을 확인할 수 있다.
리스트의 요소에 접근할 때에 한가지 조심해야 할 사항은 리스트에서 정의되지 않은 요소를 참조하고자 하는 경우에는 아래와 같이 "index out of range"라는 에러가 발생하게 된다. 만약 a = [1, 2, 3, 4] 이면 요소는 a[0] 부터 a[3] 까지 정의된 것이다. 이 범위를 벗어나면, 예를 들어 아래에서 a[4], 에러가 발생한다.

○ 리스트의 인덱스는 음수도 가능하다.
리스트도 하나의 연결된 데이터를 나타내는 "구조가 있는" 데이터 이다. 기본적으로, 리스트는 아래와 같은 이미지를 가지고 있다. 여러개의 데이터 요소가 일렬로, 순서있게 나열된 형태를 갖는다.

파이썬은 다른 언어들과 다르게 반대방향으로의 인덱싱(indexing)도 허용한다. 인덱스 0을 기준으로 순방향으로는 1, 2, 3, 4,...로 인덱스가 커지는데 비해, 0을 기준으로 역방향으로 -1. -2, -3, ... 형태로 인덱스에 음수가 나타나는 것을 허용한다. 단, 요소가 6개인 리스트에 대해, 순방향으로는 인덱스 5까지만 (인덱스 6은 out of range), 역방향으로는 인덱스 -6 까지 허용된다. 인덱스 -6과 0은 동일한 요소를 나타낸다.
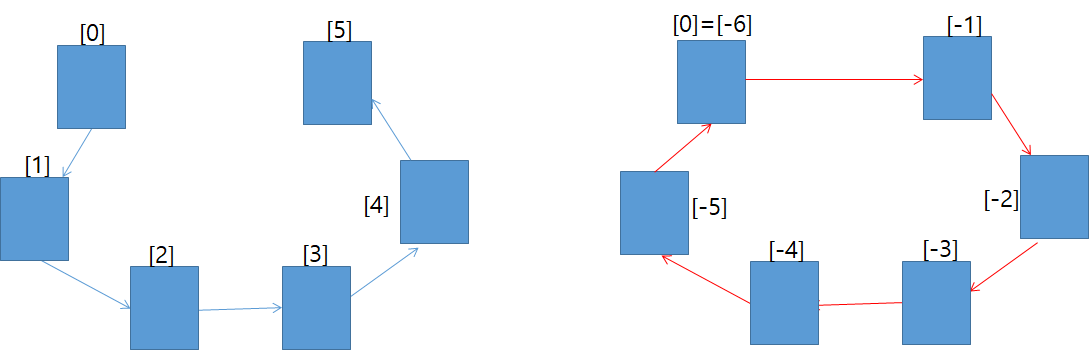
실제 코드를 통해 확인해 보자.

이와 같이, 첨자를 이용해 리스트의 각 요소에 접근하는 것을 인덱싱(indexing)이라고 한다. 이와 다르게, 전체 리스트 중 일부의 리스트에 대해서 접근할 수 도 있는데 이를 슬라이싱(slicing) 이라고 한다.
○ 리스트의 슬라이싱(slicing)
어떤 리스트 a에 대해 a[ b : c ] 라고 나타내면, 이는 전체 리스트 중 b 부터 c-1 까지에 이르는 부분 리스트를 가리키게 된다. 아래의 In[3] 처럼 슬라이싱된 리스트를 새로운 변수에 할당하게 되면, 원래 리스트에서 해당 데이터를 복사하여 새로운 리스트를 구성하게 된다.

추가적으로 슬라이싱의 사용 예를 보면 다음과 같다. In[21] 이나 In[22]에서 처럼 슬라이스의 시작값이나 끝값을 생략하는 경우에는 기준값을 중심으로 앞부분 전부 또는 뒷부분 전부를 나타내게 된다. 위에서 인덱스로 음수를 사용할 수 있음을 봤는데 슬라이스에서도 음수 인덱스를 사용할 수 있다 (In[37]). In[38]에서 처럼 시작값과 끝값을 모두 생략할 수도 있는데 이 경우에는 전체 리스트를 나타낸다.

슬라이스의 완전한 형태는 a[b : c : d] 형태이다. 여기서 d는 간격(step)이다. b 부터 시작해서 d 간격으로 c 까지 (c는 포함되지 않음) 의 값으로 구성된 부분 리스트가 된다. 아래의 사용 예를 참고하기 바란다.

○ 리스트의 몇 가지 연산들
리스트에 몇 가지 연산들이 만들어져 있다. 리스트도 하나의 데이터로 보고 + 연산과 * 연산이 만들어져 있다. (# 중요하지 않다. 확인만 하고 넘어가자...)
2개 리스트의 + 연산은 2개 리스트의 요소를 합쳐서 하나의 리스트로 만드는 연산이다.

어떤 리스트에 정수를 곱한 경우는 리스트의 요소를 그 수 만큼 반복해서 새로운 리스트를 만든다. 원래의 리스트가 변하는 것이 아님에 조심하자.

다음으로 in, not in 연산이 있다. 파이썬의 데이터 구조 중 리스트를 포함해서 시퀀스(sequence) 타입의 데이터 구조 (여러개의 데이터가 일렬로, 순서를 가지고, 나열된 형태라고 생각하면 됨) 에서 어떤 데이터가 요소 중에 포함되어 있는지, 또는 포함되어 있지 않은지를 확인할 수 있는 연산이다. 연산의 결과는 True, False로 나온다.

○ 리스트의 메쏘드 함수들
리스트도 하나의 데이터이다. 따라서, 리스트에 대해 어떤 연산들이 정의되어 있다. dir( ) 함수는 어떤 데이터(구조)에 대해 정의되어 있는 속성이나 연산들을 보여준다. dir(list), dir([1, 2, 3, 4]) 또는 dir(a) (*a가 리스트로 정의된 경우) 등의 명령어를 입력해 보면 리스트에 대해서 정의된 연산(함수)들을 보여준다. 일부만 보이면 아래와 같다.
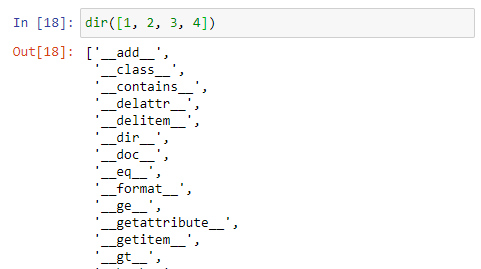
전체 내용을 콤팩트하게 보려면 dir(list) 를 print( )해 보면된다. 여기서는 list 대신에 list 객체인 a 를 사용하였다. 리스트의 특성을 보면 언더스코어(_)로 시작하는 것들이 있고, 그렇지 않은 것들이 있다. 언더스코어로 시작하는 요소들은 리스트 내부에서 활용하고자 만들어진 것으로, 리스트의 사용자에게 오픈된 것이 아니다. 우리가 사용할 수 있는 것들은 하단의 append 부터 clear, copy, ... 등이다.
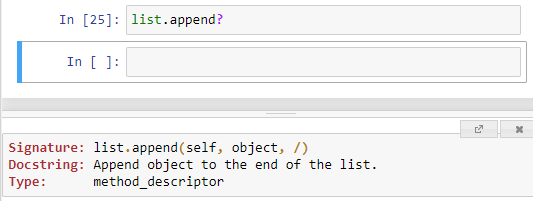
각각의 명령어에 대한 설명은 각 이름 뒤에 물음표(?)를 붙임으로써 확인할 수 있다. 예를 들어, list에서 append 가 무엇인지를 알고 싶다면 list.append? 라는 명령어를 입력하면 된다. 실제로 보이면 아래와 같다. 리스트의 append 함수는 리스트의 마지막에 argument 를 추가하는 기능이다. 만약 a=[1, 2, 3, 4] 인데 a.append(7)이라고 하면 a는 [1, 2, 3, 4, 7]로 바뀌게 된다.

참고로, 리스트를 이해하기 위해서 이 모든 함수들을 모두 테스트해 보고 알고 지나갈 필요는 없다. 필요할 때, 하나씩 하나씩 사용해 보면 저절로 알게 된다.
○ a.append(7) 의 의미?
여기서, 우리 과정에서 처음으로 보는 표식(노테이션)이 있는데, 그것은 dot( . )이다. 우리가 네번째 주제에서 다루었던[모든 프로그램은 변수와 함수로 구성된다] 에서 "모든 명령어는 d=a.b(c) 형태를 갖는다"라고 얘기를 했었다. 복습삼아 다시 살펴본다면, (# 상세한 내용은 나중에 함수, 객체를 다룰때 살펴보자. 일단은 아이디어만 가지자. 느낌이 중요하다)
(1) 가장 기본적인 형태는 b(c) 이다. "c를 d한다"로 해석하면 된다. c는 데이터이고 b는 함수이다.
(2) 행위의 주체가 있는 경우에는 a.b(c)이다. "a가 c를 b한다"로 해석하면 된다. 위의 경우와 마찬가지로 c는 데이터이고 b는 함수이다. a는 b 행위의 주체에 해당한다. 즉 누가 b 하는지를 밝힌 것이다. C나 Java에서 a는 객체(object)를 나타내지만 파이썬에서는 객체 외에도 모듈, 패키지 까지 포함되는 조금 넓은 범위이다.
(3) 행위의 결과가 있는 경우에는 d=a.b(c) 이다. "a가 c를 b한다. 그 결과는 d이다"의 의미다. 여기서 d를 리턴값(반환값, return value) 이라고 부른다.
우리가 살펴봤던 함수 중에 print(a) 형태의 함수는 주체가 생략된 형태이다. 주체가 생략되었다는 것은 주체가 파이썬이라는 것과 같다. Q: 누가 프린트해 준다고? A: 파이썬이. 너무 명확하니 생략해도 된다.
그런데 주체가 명확하지 않은 경우에는 그 주체를 밝혀 주어야 한다. append(7)은 "7을 덧붙여라" 정도로 해석할 수 있을텐데, 파이썬이 직접(?) 수행하는 작업/연산/행위/기능이 아니다. 누가 하는거라고? 그렇다. 어떤 리스트가 하는 행위이다. 그래서, a.append(7)은 "a 리스트가 7이란 데이터를 덧붙여라"는 명령어로 해석된다.
○ 리스트를 다루는 연산
리스트 데이터를 다루는 전형적인 시나리오를 하나 보이면 아래와 같다.
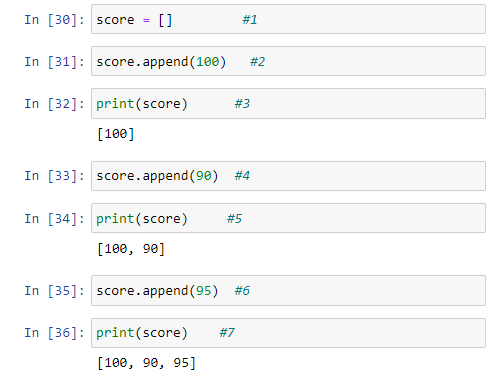
우선 #1에서 score 라는 이름의 비어 있는 리스트를 정의한다. #2에서 그 score 객체에게 100을 덧붙이라고 명령한다. 이제 score 는 1개의 요소를 가진다. 이를 #3에서 score를 print( )함으로써 확인할 수 있다. 이런 과정이 반복되면서 데이터가 완성된다.
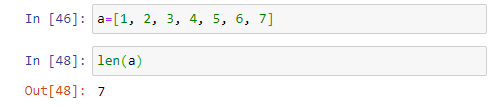
어떤 리스트의 요소의 개수를 알아야 하는 경우도 흔하게 발생한다. len( ) 라는 built-in 함수를 사용하면 된다. 아래 코드에서 Out[48]은 a 리스트의 요소의 개수가 7개임을 나타낸다.
참고로, len( ) 함수에 대한 설명은 다음과 같다. len? 를 입력하면 확인할 수 있다.

그 외에도 clear( ), copy( ), count( ), extend( ), index( ), insert( ), pop( ), remove( ), reverse( ), sort( ) 등의 연산이 제공되고 있다. 간단하게 예제 중심으로 살펴 보자. 아래의 내용들은 함수에 대한 공부가 안되어 있으면 보기 어려울 수 있으나, 함수에 대한 감을 익힐 겸 해서 한번씩은 테스트를 해보기를 추천한다.
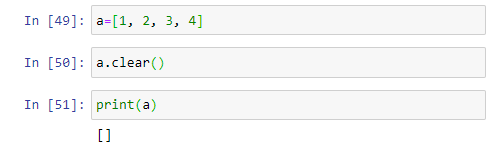
(1) clear( ) : 리스트의 모든 요소를 삭제하여 빈 리스트로 만든다
(2) copy( ) : 리스트의 복사한 새로운 리스트를 만든다.

[비교] 동일한 리스트에 대해 서로 다른 2개의 이름으로 접근하게 되는 경우와 다르다. 아래의 코드에서 b=a는 우리의 기대와 달리 a 리스트의 값을 복사한 새로운 리스트를 만드는 것이 아니라, a 리스트를 가리키는 새로운 이름을 만들게 된다. 즉, a라는 이름과 b 라는 이름은 동일한 리스트 객체를 가리키게 된다.

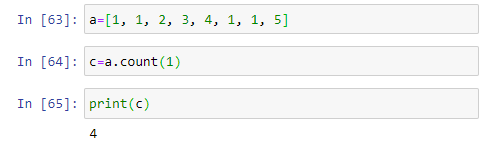
(3) count( ): 리스트에 특정한 값의 개수를 세어서 반환해 주는 함수이다. 예를 들어 a.count(1)이라고 하면 a 리스트에 포함되어 있는 요소중 1의 값을 갖는 요소의 개수를 세어서(count) 리턴 값으로 돌려주는 함수이다.
(4) extend( ) : 리스트에 다른 리스트를 추가하여 확장하는 함수이다. 예를 들어, a와 b가 리스트일 때, a.extend(b)라고 하면 a 리스트에 b 리스트를 덧붙인다. 결과적으로 a 리스트는 원래의 요소에 b 리스트의 요소를 더해서 "확장된" 리스트가 된다.

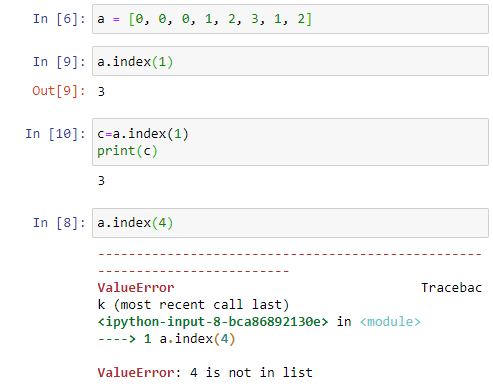
(5) index( ) : a가 어떤 리스트이고 b가 어떤 값일 때, a.index(b) 함수는 a 리스트에서 b 값이 처음으로 발견된 인덱스를 돌려준다. 아래와 같이 a 리스트에 1 이란 값이 인덱스 3과 인덱스 6에 있는데, 함수는 첫번째 인덱스인 3을 돌려주고 있다. 만약 리스트에 b 값이 없는 경우에는 에러가 발생한다.
(6) insert( ) : 리스트의 insert( ) 함수는 리스트 내에 어떤 값을 끼어 넣을 수 있는 함수이다. " (무슨) 위치에 (무슨) 값을" 끼어 넣는 함수이기 때문에, 리스트의 insert( ) 함수는 2개의 argument를 요구한다. 아래의 Signature 에서 보듯이, (첫번째 argument인 self는 볼 필요 없음. 객체 설명할 때 살펴보는 것으로 하자) 첫번째 argument는 index, 즉, 끼어 넣을 위치를 나타내고, 두번째 argument인 object는 끼어 넣을 값을 나타낸다. 실제 a=[1, 2, 3, 5] 일 때, a.insert(3, 4) 하면 인덱스 3 위치(인덱스는 0부터 시작하므로 4번째 위치. 현재는 5라는 값이 있는 위치) 에 4값이 들어가고, 5는 뒤로 한칸 밀리게 된다.


(7) pop( ) : pop( ) 함수의 argument에 삭제하고 싶은 요소의 인덱스를 넘겨주면, 인덱스가 k인 요소가 리스트에서 꺼집어 내어지고(삭제되고) 꺼집어 내어진 데이터는 리턴값으로 받을 수 있다.

pop( ) 함수의 argument 를 비워두면, 디폴트(default)로 마지막 요소가 꺼집어내어진다.

(8) remove( ) : remove( ) 함수는 argument 에 해당하는 값을 삭제하되, 첫번째로 나타난 값 (인덱스 번호가 가장 빠른 요소) 만을 삭제한다. 만약 해당하는 값이 없으면 에러가 발생한다.
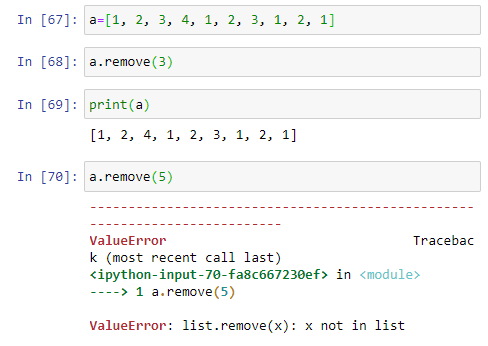
(9) reverse( ) : reverse( ) 함수는 리스트의 순서를 역순으로 바꾼다. 원래 가장 마지막에 있던 요소가 첫번째 요소가 되고, 원래 리스트에서 가장 첫번째 있던 요소가 마지막 요소가 된다.

(10) sort( ) : sort( ) 는 정렬 함수이다. 리스트에 포함된 값들을 크기의 순으로 정렬한다. sort( )는 ascending(오름차순) 으로 정렬하고, sort(reverse=True)라고 하면 descending(내림차순) 으로 정렬한다. (#reverse 파라미터는 False 값이 디폴트이다)

○ 리스트는 모든 타입의 데이터를 담을 수 있다.
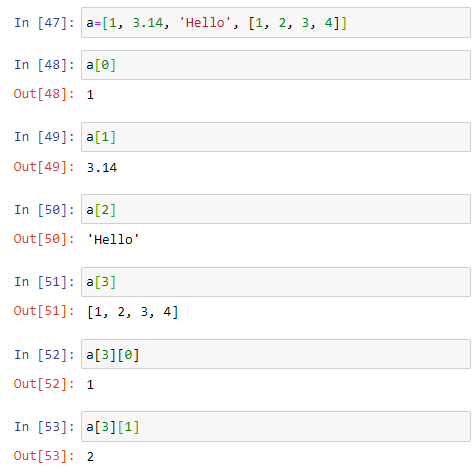
리스트는 가방(bag) 과 같은 역할을 하는 데이터 구조이다. 우리가 여행 가방 안에 옷도 담지만, 수건과 치솔도 담고, 휴대폰도 담는 원리와 같다. 실제로, 아래와 같이 리스트를 선언할 수 있다. 하나의 리스트 안에 정수 데이터도 담고, 실수 데이터도 담고, 문자열 데이터도 담고, 심지어 다른 리스트 데이터 까지 담았다.

각 각의 데이터는 인덱싱을 통해서 접근할 수 있다. 리스트 a에서 a[3] 은 리스트인데 그 리스트의 첫번째 요소는, 마찬가지로 a[3]의 [0]번째 요소란 의미에서 a[3][0]으로 접근할 수 있다 (In[52]와 In[53] 참고). 이와 같이, 첨자가 2개인 리스트를 2차원 리스트 (행렬을 연상하면 됨) 라고 부른다. 나중에, numpy 또는 pandas 패키지를 이용해서 데이터 연산을 할 때 조금 더 깊게 살펴보도록 하자.
하지만, 담는 것 보다 꺼내는 것이 더 중요하고 어렵다. 어떤 리스트 a 에서 꺼낸 첫번째 요소 a[0]가 정수인지, 실수인지, 문자열인지, 리스트인지에 따라 a[0]에 적용할 수 있는 연산이 달라진다. 여러가지 타입의 데이터가 섞여서 저장된 리스트에서 요소를 끄집어 내는 경우라면, 끄집어 내어진 데이터의 타입이 무엇인지를 항상 확인해야 하는 어려움이 있다.
알고리즘을 공부하는 입장에서, 일단, 리스트에는 (여러가지 타입의 데이터를 저장할 수 있지만) 1가지 타입의 데이터 만을 저장하는 것으로 생각하자.
'파이썬 (python)' 카테고리의 다른 글
| [python 14] 파이썬 문자열 String (0) | 2020.03.25 |
|---|---|
| [python 13] 데이터 구조 - 튜플, 딕셔너리 (1) | 2020.03.16 |
| [python 11] 변수에 대한 리뷰 (0) | 2020.02.25 |
| [python 10] 반복을 위한 for, while (0) | 2020.02.25 |
| [python 9] 분기를 위한 if, elif, else (1) | 2020.02.25 |



