
○ 알고리즘 (algorithm) 이란?
우리가 만든 파이썬 코드가 우리가 만들려고 했던 알고리즘대로 움직이는지 확인하는 과정이 필요하다. 이러한 확인 과정을 보통 테스트(test), 디버깅(debugging)이라고 부른다. 물론, 그 알고리즘이 올바르게 동작한다는 것이 검증이 되었다는 가정 하에 하는 말이다.
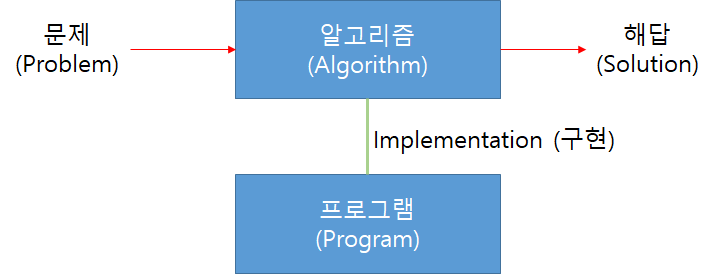
우리에게 어떤 문제 (Problem) 가 주어져 있다 (What). 우리는 그 문제에 대한 해답(solution)을 찾아야 한다. 근데 문제가 너무 복잡하여 금새 답을 떠올릴 수가 없다. 무엇인가 논리의 흐름, 즉 어떤 절차, 을 만들어야 해답을 찾아낼 수 있다. 문제와 해답을 잇는 "논리의 흐름" 을 찾는 것이 중요한데, 이를 보통 알고리즘 (algorithm)이라고 한다.

무엇(What)인가 문제가 주어진다. 우리는 그것을 해결할 수 있는 방법(How) 을 찾는다.그 방법대로 하면 어떤 답(Solution)을 얻는다. 알고리즘(Algorithm) 은 주어진 문제로 부터 해답을 찾아내는 어떤 과정이다.
보통의 경우에 해답을 찾아낼 수 있는 알고리즘은 여러개가 존재할 수 있다. 복수의 알고리즘 중에 어떤 알고리즘이 가장 좋은지, 적합한지를 알아야 한다. 그렇다면 좋은 알고리즘이란 어떤 알고리즘을 말하는 것일까? 해답을 찾는데 걸리는 시간이 짧을수록 좋은 알고리즘이다. 해답을 찾는데 필요한 비용이 적을수록 좋은 알고리즘이다. 해답을 찾는데 요구되는 자원(resource)이 적을수록 좋은 알고리즘이다. 알고리즘의 실행을 위해 필요한 자원이 범용일수록, 주변에서 구하기 쉬울수록 좋은 알고리즘이 된다.
어떻게든 알고리즘을 찾았다면, 그 다음 문제는 그 알고리즘을 자동화하는 프로그램을 개발하는 문제이다. 이때 만들어진 프로그램이 우리가 만들려고 했던 알고리즘을 실제로 구현한 (implement) 목적물이 된다.
○ 디버깅 (debugging) 이란?
우리가 프로그램을 개발하는 과정 중에, 또는 개발하고 난 후라도 계속 고민해야 하는 문제는 우리가 개발한, 또는 구현한 프로그램이 알고리즘을 충분히 잘 반영하여 논리적으로 에러(error)가 없는지에 대해 확신을 가질 수 있는지에 대한 문제이다. 내가 만든 프로그램에 대해 얼마나 확신(confidence) 하는지, 내가 만든 프로그램을 구동하면 옳은 해답을 구할 수 있다는 것을 얼마나 자신할 수 있는지에 대한 문제이다.
흔히들 "에러 없는 프로그램은 없다 (There us no software without bugs)" 라고 한다. 이 말이 소프트웨어에서 에러를 용인할 수 밖에 없다는 뜻이 아님을 잘 알 것이다. 소프트웨어를 개발함에 있어서 최선을 다해서 에러의 수를 줄이고, 에러로 인해 발생될 고장의 심각성을 줄이는 노력 (즉, 디버깅) 이 필요하다는 의미이다.
디버깅은 말 그대로 버그(bug, 벌레) 를 de- 하는 것이다. 여기서 bug는 소프트웨어에 존재하는 에러를 가리키는 말로, 실제 배추에 벌레가 있으면 배추가 상하듯이 소프트웨어에 오류가 있으면 소프트웨어의 동작을 망가뜨린다는 의미로 소프트웨어나 프로그램에 존재하는 오류(error)를 예전부터 버그라고 불러왔으며, 소프트웨어에서 버그를 찾아내어 없애는 행위를 디버그, 또는 디버깅이라고 부른다.
그래서, 디버깅은 프로그램을 만드는 과정에 필연적으로 수반되는 과정이 된다. 즉, 디버깅 되지 않은 프로그램은 프로그램이라고 부를 수가 없다. 디버깅은 다른 말로 테스팅이라고 부르기도 한다. 소프트웨어의 신뢰성(reliability)을 높이는 아주 중요한 과정이 된다.
신뢰성이란 단어가 조금 어려운 용어여서 설명을 조금 덧붙여 본다면.... 예를 들어, 여러분 앞에 자율주행 자동차가 있다. 자율주행 자동차가 하는 여러가지 기능들은 하드웨어적으로 또는 소프트웨어적으로 구현된다. 즉, 어떤 기능은 하드웨어로 개발되고, 어떤 기능은 소프트웨어로 개발된다. 만약 자동차 앞에 장애물 (obstacle)이 있는지의 여부를 CCD 카메라를 통해 입력된 화상(이미지)을 분석해서 결정하는데, 그 분석 모듈을 소프트웨어로 만들었다고 해 보자. 그런데, 이 소프트웨어가 실제로 장애물이 있는데 잘못 판단해서 장애물이 없는 것으로 오인하는 경우가 생길 수가 있으며, 그 확률이 1,000,000,000 분의 1이라고 해 보자. 여러분 같으면 이 자동차를 탈 것인가? 안탈 것인가? 참고로, 로또에 당첨될 확률은 겨우 860만 분의 1 밖에 되지 않고, 우리나라 국민 중에 평생 교통사고가 겪을 확률은 무려 35%라고 한다. 세명 중 한명은 평생동안 자동차 사고를 한번은 겪는다는 뜻이다. 그만큼 흔한 일인데, 십억분의 1이면 그냥 믿어도 되는 (reliable) 것일까?
자, 이 차를 탈 것인가? 타지 않을 것인가? 이 결정을 하는데 왠지 주저하게 되는 이유는 무엇일까? 사람과 기계 간의 차이점 중에 하나는, 사람은 환경의 변화에 적응적으로 대응하는 반면에, 기계는 그러기가 힘들다는 것이다. 즉, 사람은 앞에 장애물이 없는 줄 알고 진행하다가도 그 믿음에 착오가 있는 것을 느끼는 순간에 속도를 줄이게 되고, 결국 사고가 생기긴 하더라도 큰 사고는 피할 수 있다는 것이다. 하지만, 기계는 극히 적은 확률로 착오가 생기지만, 그 착오를 100퍼센트 확신하여 속도를 줄이지 않고 그대로 진행하여 큰 사고로 이어지게 된다는 것이다.
여태껏, 소프트웨어 개발에 있어서 테스팅과 디버깅은 매우 중요하다는 말을 한 것이다. 이제 본격적으로, 디버깅을 하는 방법에 대해서 살펴보도록 하자. 정말 다양한 방법이 있으나, 크게 화이트박스 테스팅 (white box testing)과 블랙박스 테스팅 (black box testing) 등의 2가지 방법으로 나누어 볼 수 있다. 아래에서 각각에 대해 살펴보도록 한다.
○ 블랙박스 (black box) 테스팅
블랙박스란 말 그대로 "안이 보이지 않는 박스"를 말한다. 그 박스 내에 어떤 장치가 있다고 한다면, 그 장치의 실제적인 동작을 밖에서 보지 못한다는 뜻이다. 우리가 보통 만나게 되는 거의 모든 기계나 장치가 그러하다. 자, 그럼 안이 보이지 않는 장치가 지금 고장이나 오류가 있는지 없는지 어떻게 알 수 있을까? 모든 장치는 본연의 목적이 있다. 현재 기계의 상태가 본연의 목적을 달성하고 있으면 문제가 없는 것이고, 만약 그렇지 않으면 어디엔가 문제가 생긴 것이다. 예를 들어, 시계라는 장치를 한번 가정해 보자. 시계는 "정확한 시간을 알려주는" 목적을 가진 장치이다. 만약 시계 초침이 움직이지 않는다든가 우연히 서울역 시계탑에서 본 시각과 내 손목시계의 시각이 다르다면 내 손목시계에 오류가 생겼다는 것을 알 수 있을 것이다. 그러면, 내 시계에 오류가 생긴 것을 파악하게 되고, 최대한 빨리 그 오류를 해결하기 위한 조치를 취하게 될 것이다. 소프트웨어 블랙박스 테스팅도 이와 다르지 않다.
우리가 디버깅하는 대상은 하나의 기능 단위에 해당하는 하나의 함수이다. 실제 그 함수는 다음과 같이 동작한다. 해당 함수에 어떤 입력데이터를 주면, 함수 내에서 정해진 절차에 따라 그에 해당하는 출력데이터가 만들어지게 된다.

예를 들어, 우리 함수가 팩토리얼(!) 값을 계산하는 함수라고 하자. 함수의 이름은 fact( )라고 하면 좋을 것이고, 매개변수는 하나의 정수 값이다.

이 함수를 호출할 때 n에 어떤 정수값 인자를 전달하게 된다. 예를 들어 fact(5). 여기서 5가 fact 함수의 입력값에 해당한다. 그러면 fact 함수는 내부의 정해진 절차에 따라 (아마) 5*4*3*2*1 인 120을 계산하여 출력해 줄 것이다.
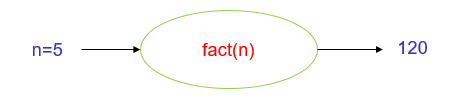
위의 그림에서 보다시피, 출력(y)은 입력데이터(x)와 절차(f)에 따라 달라진다. 결국 y = f(x) 인 것이다. 무슨 말이다? 우리가 만든 fact( )함수가 올바로 동작하는지는 입력데이터를 임의로 줬을 때, 출력데이터가 우리가 기대하는 값을 확인함으로써 확인할 수 있다. 이와 같이, 하나의 입력데이터와 하나의 출력데이터를 묶어서 테스트 케이스(test case)라고 부른다. 보통 (I, O) 로 나타내는데, 우리 문제의 경우에는 (5, 120)인 셈이다.
그런데, 우리가 경험으로 부터 알 수 있듯이, 중간에 절차가 틀렸더라도 우연히 한두번은 정답이 나오는 경우가 있다. 그래서 함수를 디버깅하는데 하나의 테스트 케이스를 사용하지 않고 여러개의 (가능한 많은 수의) 테스트 케이스를 준비해서 실제 디버깅을 진행하게 된다. 예를 들어, 우리가 만든 fact 함수를 테스트하기 위한 테스트 플랜(test plan)은 다음의 표와 비슷한 형태가 될 것이다.
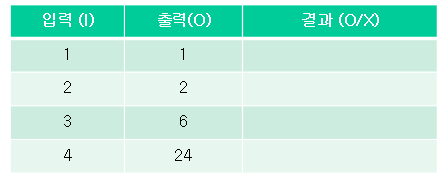
위 테이블의 각 행이 하나의 테스트케이스가 된다. 각 테스트 케이스의 입력값을 함수에 넣어주고 실제 해당하는 출력이 나오는지를 확인한 후 결과에 O, X 를 마크하면 되겠다. 우리의 경우에는 4개의 경우만을 테스트하는 것으로 계획을 세웠는데, 4가지 모두에 O가 나오면 테스트를 통과한다. 내부에 오류가 없는 것으로 판단할 수 있겠다.
아주 단순하고 어쩌면 당연한 방법이다. 그런데, 이 방법에는 한가지 어려움이 있다. 그것은 함수를 테스트 하는데 충분하려고 하면 도대체 몇개의 테스트케이스를 테스트해야 하는지, 그리고 어떤 값들을 테스트해야 하는지 하는 문제이다. 우리의 경우라면, 4개 정도의 테스트케이스면 함수가 제대로 만들어졌는지, 내부에 오류가 있는지를 확인하는데에 충분한 건지, 충분하지 않다면 도대체 얼마나 많은 테스트케이스를 준비해야 하는지에 대한 고민이다.
정답은 없다. 함수(함수라고 쓰고, 소프트웨어라고 읽자) 의 기능이 무엇인지에 따라서 당연히 달라지겠지만, 그외에도 함수를 테스트하는데 허용되는 시간, 비용, 그리고 그 함수가 오작동하는 경우에 발생할 수 있는 사고의 유형, 크기에 따라서도 테스트 플랜은 달라져야 한다.
○ 화이트박스 (white box) 테스팅
+ Brute Force (맹목적 강요)
** 자세한 내용은 [파이썬 알고리즘 객체지향 코딩의 기술] 를 참고하기 바랍니다 **
'파이썬 (python)' 카테고리의 다른 글
| [python 24] 알고리즘 연습 - 4 : 두번째로 큰 값 찾기 (0) | 2020.04.25 |
|---|---|
| [python 23] 알고리즘 연습 - 3 : 정렬 알고리즘 (0) | 2020.04.16 |
| [python 21] 사용자 정의 식별자와 참조 범위 (0) | 2020.04.10 |
| [python 20] 알고리즘 연습 - 2 (0) | 2020.04.01 |
| [python 19] 알고리즘 연습 - 1 (0) | 2020.03.30 |



